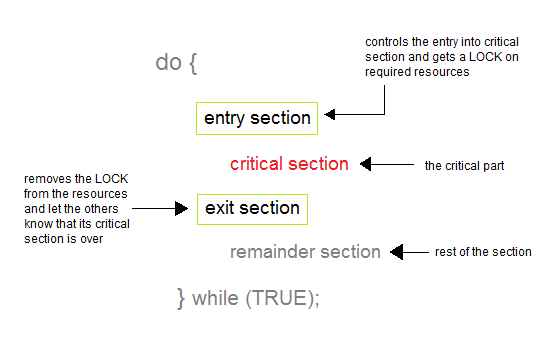
이전에 들었던 수업은 하드웨어를 이용한 동기화 시스템에 대해서 이야기 하였다.
test_and_set()과 compare_and_swap()에 관련된 시스템 콜 기반 Critical Section을 활용한 동기화 Solution에 대해서 말이다.
이번에 배운 것은 하드웨어 동기화 Solution이다.
그 첫번째
Mutex Locks(=Mutual Exclusion Lock)
Mutex Lock에는 두 가지 함수가 존재한다.
Lock을 차지하는 acquire()과 Lock을 놓아주는 release()
두 함수가 어떻게 description되어 있는지를 확인하면

 -> description
-> description
이렇게 구성이 되어있다.
코드를 보면 구성이 매우 심플하다 ㅎㅎ
물론 위의 코드는 소프트웨어적으로 처리하는 것이 아닌, 하드웨어적으로 처리하게 된다.
(acquire과 release는 무조건 atomic해야 하기 때문이다.)
하지만 위의 함수에서 가장 큰 Issue가 있는데, 바로 busy_waiting이다.
고가의 cpu를 열심히 돌리는데... 결과론적으로, waiting이라니... 이 얼마나 낭비인가.(spinlock이라고도 불린다.)
이러한 문제에 대한 해결책은 다음장에서 배운다고 하니 일단 넘어가자.
다음으로 배운 것은
semaphore이다.
semaphore의 기원을 한 번 알아보자.

semaphore를 인터넷에 검색하니깐 이러한 그림이 나왔다.
이 그림은 무엇일까...?

바로 빨간색 네모 박스를 의미한다.
저 기찻길 신호등과 기찻길 사이의 공간에는 기차와 차 또는 사람이 같이 들어갈 수 없다. semaphore도 어떠한 자원을 여러명이서 차지할 수 없다는 뜻에서 이름을 이렇게 지었나보다.
각설하고 semaphore를 조금 더 자세히 들여다 보면, Lock과 달리 S라는 variable이 존재한다. 이는 가용 자원수로서 해당 자원을 몇 명의 사람이 사용할 수 있는지를 결정한다.
예를 들어 학교에 학생들을 프로세스, 체육 선생을 semaphore라고 하고, 축구공을 공유자원이라고 하자.
체육 선생이 축구공을 4개 가지고 있다면 S = 4가 되는 것이고, 이는 4개의 process가 각각 사용할 수 있는 것이다.
이 S 변수는 학생이 축구공을 소지하면 개수가 감소하고(S--) 다시 돌려주면 개수가 증가한다(S++)
그리고 전자의 과정을 wait(), 후자를 signal()이라고 한다.
Mutex Lock에서 acquire()과 release()와 동일한 기능을 수행한다.
그리고 어떠한 책에서는 P(), V()라고도 표현하는데 다 같은 의미라고 보면 되겠다.
무튼 wait()와 signal() 함수는 아래와 같은 동작을 수행한다.

S가 0이하라면 semaphore의 공유 자원의 개수가 없는 것이므로 대기한다.
그렇지 않다면 S--를 수행해 가용 자원수를 감소시킨다.
signal()은 자원을 돌려놓는 것이므로 가용 자원수를 증가시킨다.
semaphore의 종류는 크게 2가지 입니다.
* Counting semaphore
- S > 1
* Binary Semaphore
- S == 1
- Binary Semaphore는 Mutex Lock과 동일한 역할을 수행한다고 보면 된다.
기본적으로 Semaphore는 다양한 사용법이 있는데 그 중 하나
1. P1의 S1 다음에 P2의 S2를 수행하고 싶은 경우

위의 코드를 한 번 보자.
synch = 0으로 초기화한다고 가정한다.
wait() 함수의 경우 parameter가 0일 경우 대기하게 되고,
signal()함수는 S1작업이 모두 끝나게 되면 호출되어 synch++을 수행하게 될 것이다.
이렇게 하면 자연스럽게 각 Process 간에서의 동작도 수행 순서를 설정할 수 있게 된다.
하지만 이 semaphore도 문제가 있다. 바로 busy_waiting 문제!!!

busy_waiting을 해결하기 위해서는 Process의 Waiting 상태(=Blocked)를 이용하는 것이다.
이와 관련된 list를 하나 생성하고, wait가 필요하다면 list에 push후 block시킨다. - (1)번
그리고 조건을 만족하면 list에서 process를 pop하고 wakeup 시킨다. - (2)번

그렇게 변경된 wait()와 signal() 함수.
semaphore라는 구조체가 하나 생성이 되었고, 해당 구조체는 value(=S), list(=wait_list) 두 개의 인자를 가진다.
wait() 함수가 호출되면 이전처럼 busy_waiting 후 가용 자원수를 감소시키는 것이 아닌, 일단 가용 자원수(value)를 감소시킨 후 해당 자원수가 음수일 경우 대기해야 하므로, list에 해당 process를 push한 후 block()시킨다.
signal() 함수의 경우 가용자원수를 다시 늘리는 작업 뿐만 아니라, list에 process가 들어가 있을 경우(S->value <= 0을 만족하는 경우) list에 있는 process를 제거시켜주고, 해당 process(현재 process가 아님)를 깨운다.
Ex)
A라는 process에서 wait()를 호출하고, B라는 process에서 wait()를 호출하였고, semaphore의 value는 1이라고 가정해보자.
A라는 process에서 wait()를 호출하게 되면, semaphore->value는 0이 되고, critical section에 들어가서 필요한 작업을 수행하게 될 것이다. 그 사이에 B Process에서 wait()를 호출하게 되면 B Process는 block 상태에 들어가게 될 것이다.
그 후 A process의 Critical Section에서 모든 작업이 종료되고, signal()을 수행하게 되면 list에 들어있던 B process를 꺼내 wakeup(=unblock)을 수행하게 될 것이다.
그렇게 B process wait()이후부터 동작을 수행하게 될 것이고 critical section 작업을 수행할 것이며 그 당시 semaphore->value는 0을 유지하고 있을 것이다.
자 이제 이렇게 동기화 작업 사이에서 발생할 수 있는 문제점들에 대해서 한 번 이야기를 해보자.
이야기할 문제는 크게 3가지가 있다.
1. Deadlock
* 두 개 이상의 Process가 서로를 기다림으로써 발생하는 문제. Program이 멈춰버리게 된다.
2. Starvation
* Priority 등에 의해서 어느 하나의 process가 동작하지 못하고 굶어 죽는 현상
3. Priority Inversion
* 이 역시 priority에 의해서 더 낮은 process가 더 높은 process보다 먼저 수행되는 현상.
* 이 현상은 priority-inheritance protocol을 이용하여 해결할 수 있다.
위에서 언급한 문제들을 일반화시켜 설명해보려 한다.
1. Bounded-Buffer Problem
Bounded-Buffer Problem은 Producer-Consumer 사이에서 발생할 수 있는 문제이고, semaphore를 이용하여 해결할 수 있다.
Producer
|
Consumer |
 |
 |
여기서는 value가 3종류가 사용되었다.
semaphore empty
semaphore full
semaphore mutex
n개의 buffer가 있다고 가정하였을 때
mutex = 1, full = 0, empty = n으로 초기화를 수행한다.
Producer는 Buffer에 데이터가 꽉 차 있을 경우에는 기다려야 한다.
코드를 보면 가장 먼저 wait(empty)를 수행하게 되는데, wait() 함수는 parameter 값을 일단 감소시키고, 감소된 결과 값이 0 미만일 경우 대기하게 된다. 따라서 empty < 0일 경우는(=Buffer에 빈자리가 없을 경우 = Buffer가 꽉찬 경우) wait를 수행하고, 그렇지 않을 경우는 wait(mutex)를 지나 buffer에 값을 쓰기 시작한다.(=buffer에 값을 넣거나 빼는 행위는 atomic하게 수행되어야 한다.)
writing 과정이 모두 끝나면, signal()을 이용하여 mutex에 대한 lock을 해제해주고, full에 대한 lock 역시 해제한다.
signal() 함수는 가용 자원수를 증가시키는 역할을 수행한다. 즉, full이 0이라는 의미는 현재 Buffer에 사용가능한 데이터가 없다는 의미=사용할 수 있는 데이터가 없다는 것이다.
이러한 맥락에서 Consumer도 쉽게 해석이 되리라 생각된다.
2. Reader- Writers Problem
이번에는 읽는 사람과 쓰는 사람간의 문제이다.
읽는 사람은 누가와서 읽어도 상관없지만, 쓰는 사람은 그 순간에는 최대 1명이 되어야 한다.
이러한 동작을 위해서 3개의 변수가 사용된다.
semaphore rw_mutex = 1
semaphore mutex = 1
int read_count = 0
그리고 Reader-Writers Problem에서는 문제를 해결하기 전에 다양한 가정을 산정지을 수 있다.
(1) writer가 공유 자원에 대한 권한을 가지고 있지 않다면, reader는 waiting할 필요가 없다.
(2) writer가 준비가 되면 바로 writing을 수행해야 한다.
이 두 가지 경우 모두 starvation이 발생할 수 있다.
이번 수업에서는 (1)의 경우에 대해서만 코드를 확인해 보았다.
writer |
reader |
 |
 |
writer는 간단하다. 읽고 쓰는 사람이 없으면 들어가서 쓰면 된다.
reader의 경우는 살짝 복잡하다.
read_count라는 변수를 증가시키기 위해 mutex semaphore를 이용하여, 다른 process가 실행되지 못하게 하고, count를 증가시킨다. 만약, read count == 1이라면 가장 먼저 공유 자원을 읽으려는 process이므로, 혹여 writer가 있나 없나를 체크 하고 없다면 signal()을 이용해 read_count에 대한 critical section을 종료한다.
이렇게 되면 현재 rw_mutex = 0인 상태이기 때문에 writer는 접근을 할 수 없다. 하지만 다른 reader들은 얼마든지 접근이 가능하다.
read가 다 끝났으면 다시 read_count를 감소시켜주기 위해 wait(mutex)를 실행하고, read count--를 수행한다.
만약 read count가 0이라면, 읽는 사람이 없다는 뜻이므로, rw_mutex를 증가시킨다.
이렇게 하면 reader writer problem의 (1)번 경우가 해결된다.
3. Dining Philosophers Problem

해당 그림에서 5명의 사람(Process)가 있고, 5개의 젓가락(Shared resource)가 있다. 그리고 하나의 프로세스는 자신의 양 옆에 있는 두 개의 젓가락을 사용할 수 있다.
여기서 발생할 수 있는 문제는 바로 DeadLock이다.
이러한 코드가 있다고 가정해보자.
각각 따로 실행이 잘 된다면 문제가 없을 것이다. 하지만 5개의 process가 동시에 젓가락을 탐한다고 해보자.
만약 모두가 왼쪽 젓가락을 원했다. 그래서 왼쪽 젓가락을 사용할 수 있는 것을 확인하고, 오른쪽 젓가락을 확인해보니 모든 젓가락이 사용중인 것이다. 이렇게 되면 각 Process가 서로서로를 기다리게 되고, 결과적으로 시스템이 멈춰버리는 DeadLock 문제가 발생하게 된다.
오늘 배운 것은 바로 여기까지~