컴퓨터 관련 분야에서 가장 중요한 것은 영어다.
격언 : 컴퓨터를 잘하는 사람에게 영어를 가르치는 것보다 영어를 잘하는 사람한테 컴퓨터를 가르치는 것이 더 낫다.
자신의 의견을 어필하기 위한 수단이 영어다.
영어 공부 열씨미 하즈아아
각설하고, Synchronization에 대해서 오늘은 공부하였다.
동기화 문제가 발생하는 이유는 바로 일관성(consistency)가 깨지기 때문이다. 만약 하나의 코어에서 하나의 process만 동작한다면 동기화가 필요 없겠지만, 다양한 process가 다양한 코어에서 사용되다 보니 일관성이 깨져 동기화 문제가 발생하게 되는 것...
이러한 문제를 해결하기 위한 방법으로 소프트웨어적인 방법과 하드웨어적인 방법 크게 두 가지가 존재한다.
아, 문제 해결 방법을 정리하기 전에 동기화 문제에 대해서 예시를 한 번 들어보자.
자, 예전에 공부했던 Producer-Consumer Problem에서 우리는 circular queue를 구현하여, 버퍼를 만들어 사용하였다. 이 때 empty와 full을 구분하기 위해 귀중한 buffer 하나를 사용하지 않으면서 말이다.
그런데 한가지 궁금증이 생긴다. 그냥 counter라는 공유 변수를 놓고 버퍼가 차면 하나 증가시키고, 버퍼가 빠지면 하나 감소시키면서 관리하면 되지 않는가?
여기서, 동기화 문제가 발생한다. HLL(=High Level Language)에서 한 줄은 실제 여러줄로 동작될 수 있다.
예를 들어, counter++ 이라는 명령어를 실제로 instruction set 단계로 내려가면
register1 = counter (LOAD)
register1 = register1 + 1 (ALU)
counter = register1 (STORE)
3가지 단계를 거치게 된다.
그런데 이 때 Race Condition이라는 문제가 발생하게 된다.
Race Condition이란?
한국 말로 "경쟁 상태"로서 둘 이상의 입력 또는 조작의 타이밍이나 순서 등이 결과값에 영향을 줄 수 있는 상태를 말한다.
- 위키
즉, 실행 순서에 따라서 결과가 다르게 나올 수 있다는 것이다. 말이 되는가? counter++을 했는데 결과가 2개 이상이 나올 수 있는 경우가 있다는 것이?????!!!!!!
결론은 가능하다!
자 예를 한 번 들어보자.
2개의 Process가 존재하고, 각 Process에서 counter++, counter--를 수행해보자.
각 명령은 3개의 instruction set으로 존재하고, 하나의 instruction이 atomic한 경우를 만족한다고 가정하면, context-switching은 instruction과 instruction 사이에서 발생할 수 있을 것이다.
만약 counter++, counter--를 수행하게 되면 초기값이 5였을 때 최종 결과는 항상 5가 되어야 하는데...
register1 = counter
register1 = register+1
------------------------------> context-switching 발생
register2 = counter
register2 = register -1
------------------------------> context-switching 발생
counter = register1
------------------------------> context-switching 발생
counter = register2
위의 과정을 거치면 counter 값은 4가 된다.
위와 같은 경우로 인해 우리는 circular queue에 두 개의 variable을 두고 Producer와 Consumer가 건드릴 수 있는 variable을 각각 설정한 것이다.(이는 공유 자원이 아니다!)
어떠한 이유로 동기화 문제가 발생하는 것을 알았으니, 어떻게 하면 이러한 문제가 발생하지 않을까?
"하나의 Process가 공유 자원을 사용하면 다른 Process는 공유 자원에 접근할 수 없다"
로 해결할 수 있을 것 같다.
좀 더 자세하게 들어가보자.
운영체제에서는 Cirtical Section Problem이라는 것이 있다.
Critical Section(<->remainder section)이란 상호 베타적인 접근을 보장해주는 영역으로서 각 Process마다 Critical Section을 가지고 있고, 어떠한 Process가 Critical Section에서 작업하고 있다면 다른 Process는 Critical Section에서 작업을 할 수 없는 것이다.
Problem은 어떻게 상호 베타적인 접근을 보장해주냐는 것을 의미하고 말이다.
이러한 Critical Section에 들어가기 위한 entry Section 나가기 위한 exit Section이 추가적으로 있고, 이를 그림으로
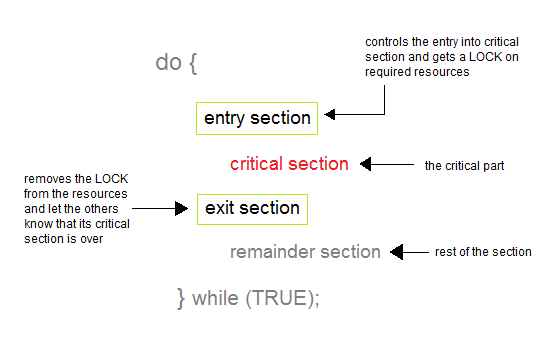
이와 같이 볼 수 있다.
자 이제 해결해야 할 문제는 어떻게 critical Section의 상호베타적 접근을 보장해주기 위한 해결책을 해.............보기 전에
Critical Section Problem에 대한 기준 3가지를 한 번 언급해보려 한다.
1. Mutual Exclusion
-> "상호 배제". 즉, 베타적인 접근을 보장해야 한다는 기준이다. critical section을 사용하는 가장 근본적인 이유라고 하겠다.
2. Progress
->"진행". Critical Section이 무기한 연기될 수 없다. 하나의 Critical Section이 다른 Critical Section에 의해 무기한 연기될 수 없다는 기준이다.
3. Bounded Waiting
-> "한계가 있는 기다림". 어떻게 보면 2와 동일한 말이다. 무기한 연기될 수 없으니깐 기다림에 있어서 제한을 둬야 한다는 기준이다.
이 3가지 기준을 모두 만족해야만 Critical Section Problem을 해결했다고 볼 수 있는 것이다.
그렇다면 구체적으로 들어가서 보자!
먼저 SW Solution을 분석해보자.
Peterson's Solution
위의 솔루션은 제한 조건이 있다.
1. 두 개의 Process에 대한 Solution
2. load, store instruction이 atomic하다. -> 요즘 시스템에는 맞지 않는 말이다.
그리고 2개의 variable을 사용한다.
1. int turn -> Critical Seciton에 누가 들어갈 것인지를 알려주는 변수
2. Boolean flag[2] -> Critical Section에 들어갈 것이라는 의사표시를 하는 변수
프로세스가 2개(Pi, Pj / i = 0, j = 1)가 있다고 했을 때 Peterson's Solution의 알고리즘은 아래와 같다.

entry_section에서 본인의 flag를 true로 바꾸고 turn값을 다른 process로 명명한다.
그리고 while문을 돌며 다른 process의 flag가 true이고, turn == 1일 경우 자신은 대기한다.
여기서 특이한 점은 P0에서 turn = 1을 수행하는 것인데.... 이는 turn에 대한 Consistency가 깨져도 Race Condition이 발생하지 않게 하기 위함이다.
해당 알고리즘은 두 개의 Process가 Critical Section에 접근하지 않으면 되는 것이다.
그렇다면 어떠한 경우에 while문을 빠져 나올 수 있는지를 확인해보자.
P0의 경우
flag[1]==false or turn == 0인 경우이고,
P1의 경우
flag[0] == faluse or turn == 1인 경우이다.
다른 process가 Critical Section에 들어갈 필요가 없다면(flag == FALSE), 내 process는 critical section에 들어가서 작업을 하면 되는 것이고,
flag가 모두 TRUE라면, turn에 의해서 가장 최근에 실행된 process와는 다른 thread가 critical section을 수행하게 된다.
다음으로는 HW Solution을 한 번 확인해보자.
HW Solution의 핵심은 검사와 값 변환을 한 번에 수행하는 것이다. sw라면 수행할 수 없지만 hw이기 때문에 두 개의 행동이 동시에 실행이 가능한 것.

lock이 False였다면? Lock을 가지고 있는 Process가 없다는 의미니깐, 내가 쓸게 하고 lock을 true로 변경해주고, 이전 값을 반환하게 되면, critical section으로 들어가 동작을 수행한다.
lock이 true면 누군가가 사용하고 있다는 의미니깐 계속 while문을 돌며 대기한다.
compare_and swap도 동일한 기능을 수행한다. 단지 compare과정(lock의 값이 내가 예상하는 값이 맞는지 확인)이 추가된 것일 뿐...
하지만 위의 방식처럼만 사용하게 되먼 Bounded Waiting이 보장되지 않는다.
그래서 아래와 같이 사용한다.

waiting[] 배열은 나 critical Section에 들어가고 싶어! 라고 하는 process들이 표시를 해놓는 공간이다.
Entry_Section
즉, a라는 process가 나 critical section 수행할거야! 라고 하면 waiting[a]를 true로 만들어주고, key값도 true로 만들어주고 기다린다.
key가 true이므로 while은 무조건 한 번 이상은 수행이 될 것이고,
test_and_set()에서 lock이 true라면(lock을 사용하고 있는 process가 있다면) key값은 계속 true를 유지할 것이고,
test_and_set()에서 lock이 false가 된다면 key 값은 false가 되어 critical section을 수행할 것이다.
End_Section
waiting배열을 circular하게 돌아가게 설정을 해놓는다. 즉, j는 i의 바로 옆 배열이라는 소리.
이 때 옆 배열이 나 자신이 아니고, waiting[j] = FALSE일 때는 j를 하나 더 증가시켜준다.(=다음 process는 critical section에 들어가지 않을거야 라는 의미)
그렇게 비교를 하다가 critical section에 들어갈 거야하는 process가 나올 경우 lock은 true를 유지한 채 waiting값만 false로 만들어 critical section으로 들어가게 한다.
만약 한바퀴를 돌아도 waiting이 true인 곳이 없다면 lock을 해제한다.
이게 어떻게 bounded waiting을 만족시키느냐??
index를 변경해가면서 waiting을 검사하므로 priority가 상대적으로 동작하게 된다. 따라서 bounded waiting을 자동적으로 만족하는 것!


